
Training ESM2 LLM on GKE using BioNeMo Framework 2.0
This samples walks through setting up a Google Cloud GKE environment to train ESM2 (Evolutionary Scale Modeling) using NVIDIA BioNeMo Framework 2.0
Table of Contents
Prerequisites
-
GCloud SDK: Ensure you have the Google Cloud SDK installed and configured.
-
Project: A Google Cloud project with billing enabled.
-
Permissions: Sufficient permissions to create GKE clusters and other related resources.
-
kubectl: kubectl command-line tool installed and configured.
-
NVIDIA GPUs: One of the below GPUs should work
-
Clone the repo before proceeding further:
git clone https://github.com/ai-on-gke/nvidia-ai-solutions cd nvidia-ai-solutions/bionemo
Setup
-
Set Project- Replace “your-project-id” with your actual project ID.
gcloud config set project "your-project-id" -
Set Environment Variables:
export REGION=us-central1 export ZONE=us-central1-a export CLUSTER_NAME=bionemo-demo export NODE_POOL_MACHINE_TYPE=g2-standard-24 #e.g., a2-highgpu-1g (A100 40GB) or a2-ultragpu-1g (A100 80GB) export CLUSTER_MACHINE_TYPE=e2-standard-2 export GPU_TYPE=nvidia-l4 # e.g., nvidia-tesla-a100 for A100 40GB OR nvidia-a100-80gb (A100 80GB) export GPU_COUNT=2 # e.g., 1 (A100) export NETWORK_NAME="default"Adjust the zone, machine type, accelerator type, count, and number of nodes as per your requirements. Refer to Google Cloud documentation for available options. Consider smaller machine types for development to manage costs.
-
Enable the Filestore API:
gcloud services enable file.googleapis.com -
Create GKE Cluster:
gcloud container clusters create ${CLUSTER_NAME} \ --location=${ZONE} \ --network=${NETWORK_NAME} \ --addons=GcpFilestoreCsiDriver \ --machine-type=${CLUSTER_MACHINE_TYPE} \ --num-nodes=1 -
Create GPU Node Pool:
gcloud container node-pools create gpupool \ --location=${ZONE} \ --cluster=${CLUSTER_NAME} \ --machine-type=${NODE_POOL_MACHINE_TYPE} \ --num-nodes=1 \ --accelerator type=${GPU_TYPE},count=${GPU_COUNT},gpu-driver-version=latestThis creates a node pool specifically for GPU workloads.
-
Get Cluster Credentials:
gcloud container clusters get-credentials "${CLUSTER_NAME}" \ --location="${ZONE}" -
Create namespace, training job, tensorboard microservice, and mount Google cloud Filestore for storage
alias k=kubectlThen run:
k apply -k pretraining/
Wait for 10-15 minutes to complete the file store mounting and job training. The dataset used in the walkthrough is a small sampling. It could take 8-10 minutes for data to be downloaded and all the steps to be completed. Upon successful completion of pre-training job, below message will be displayed.
Trainer.fit stopped: `max_steps=100` reached.
-
Port Forwarding (for TensorBoard):
List PODs and ensure tensorboard POD is under
Runningstatusk get pods -n bionemo-training
It is assumed that the local port 8000 is available. If the post is unavailable, update below to an available port.
k port-forward -n bionemo-training svc/tensorboard-service 8080:6006
-
View Tensorboard logs
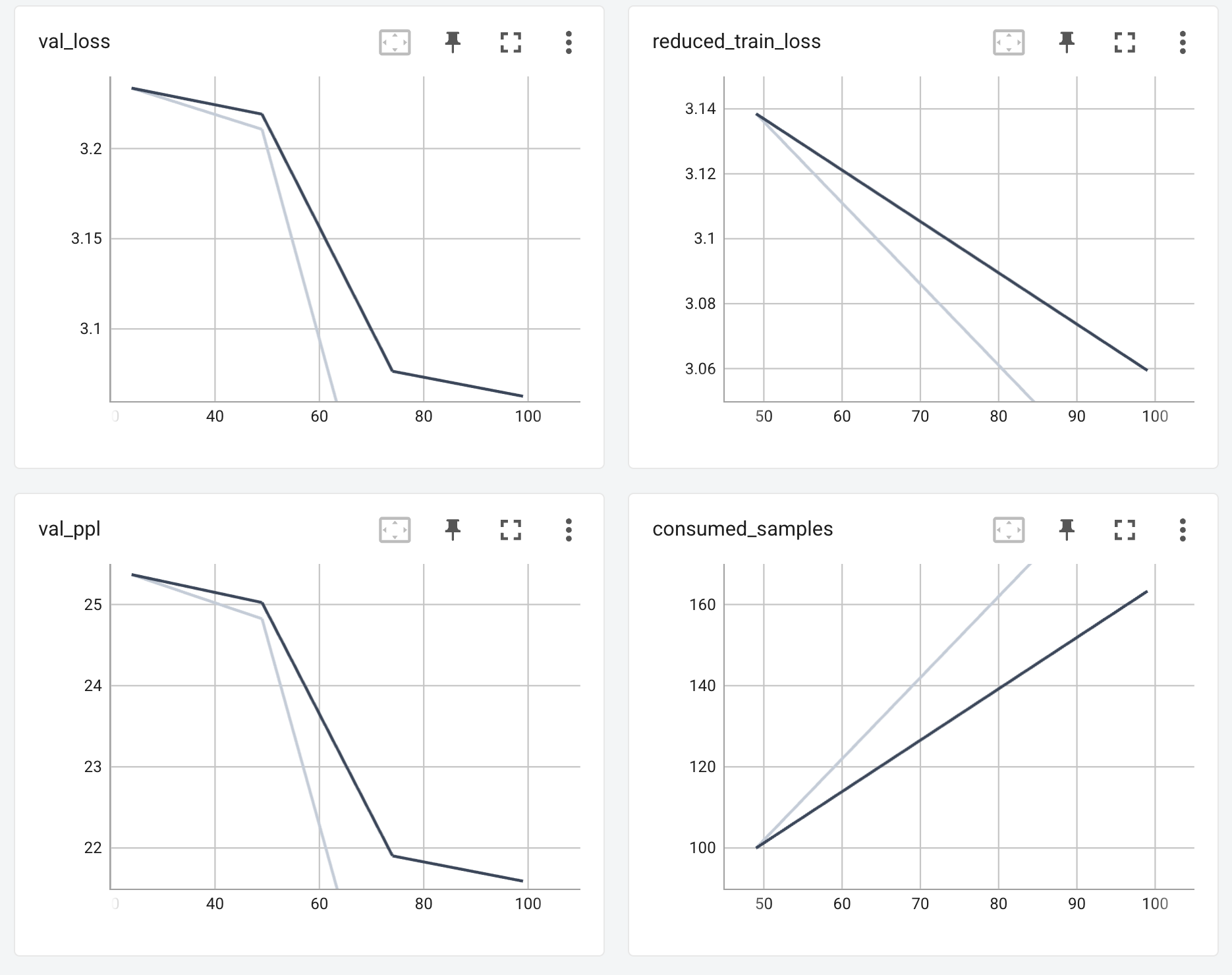
On your local machine: Browse to http://localhost:8080 port forward from above step timeseries and see the loss curves as show below.
Tensorboard dashboards will take some time to show up as the bioenemo job takes a few minutes to kick off. Then, the full plots will show up once the job’s POD is under COMPLETED status.
Cleanup
-
Delete all associated resources
k delete -k pretraining/
This cluster can be used for fine-tuning. Feel free to skip the next step if you want to reuse it.
-
To delete the cluster
gcloud container clusters delete "${CLUSTER_NAME}" --location="${ZONE}" --quiet